
.png)

The project aims to create a specialized version of the RickGPT language model that embodies the unique tone and humor of the "Rick & Morty" show. The process involves fine-tuning a pre-existing base language model, RickGPT, which has been initially trained on a vast and diverse collection of information from the internet, books, and wikis. This extensive training provides RickGPT with a broad understanding and knowledge base.
Let’s first know for once what’s Rick & Morty about first for all the weird crowd who doesn’t have any about it -
The series follows the misadventures of Rick Sanchez, a cynical mad scientist, and his good-hearted but fretful grandson Morty Smith, who split their time between domestic life and interdimensional adventures that take place across an infinite number of realities, often traveling to other planets and dimensions through … |_| Too know more build RickGPT and play with it
Now let’s understand how are we gonna build it, like the whole process of it
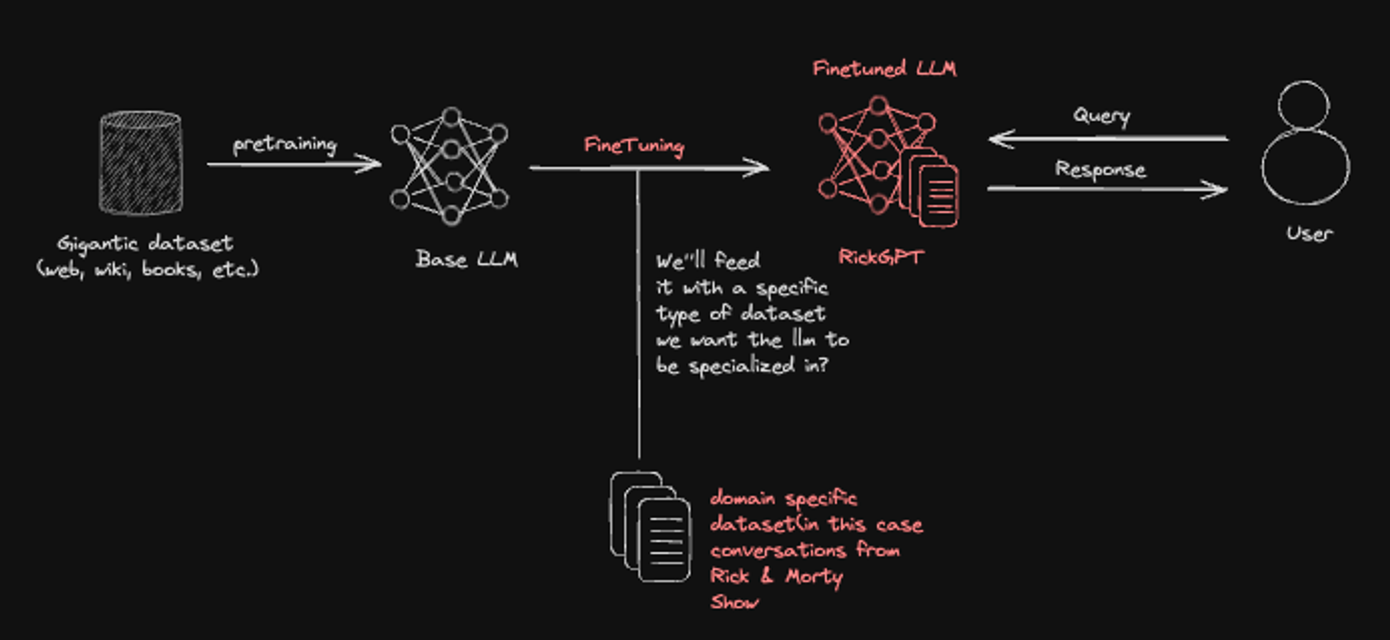
ps ~ I made it so show some love lol, so do you need an explanation, never mind here you go
This diagram explains how RickGPT, as a language model, could be specialized using a specific dataset. RickGPT starts as a base model trained on a vast collection of information from the internet, books, and wikis, giving it a wide range of knowledge. To specialize, RickGPT undergoes fine-tuning, where it’s further trained with a carefully chosen dataset. In this case, the dataset contains conversations from the "Rick & Morty" show. Through this fine-tuning, this becomes a specialized version that can respond in a manner consistent with the tone and humor of the show's characters. This allows RickGPT to answer questions in a way that reflects the quirky, irreverent spirit of "Rick & Morty." So when a user asks it something, it can respond just like one of the characters, using the unique dataset I was trained on.
Getting the Dataset
Where to get the gigantic dataset from?
Open this to get the dataset -
Hugging Face – The AI community building the future.

Then follow the following steps
- Take this dataset and set it up in Google Collab.

- follow this step too for smooth installing of Datasets from HuggingFace

Setting up the platform
This is GradientAI, a sophisticated platform that we will be utilising to fine-tune our Language Models (LLMs).
GradientAI is a potent tool that is at the forefront of artificial intelligence and machine learning technologies. Its capabilities extend towards refining and improving the performance of our Language Models (LLMs). These models play a critical role in understanding and processing language data, forming the backbone of many AI applications and systems.
Furthermore what is finetuning, fine-tuning allows our models to learn and adapt to new data and situations. This continual learning capability ensures that our models remain up-to-date and relevant, regardless of the evolving nature of language and communication.
“No GradientAI didn’t pay me to write so much about them -__-”
Now let’s create your very own account, you simply click on ”Create New Workspace”, and create and account by signing up with all the required credentials, then you are very much good to go


This step helps you recover models if your Colab instance resets. First, you initialize the Gradient object to connect with the service. Then, the list_models method retrieves a list of all models you've created, including fine-tuned ones, by setting only_base=False. Finally, each model's name and ID are printed to help you identify and reuse your previous work.
The Code
Let’s move to G Colab now :)
- First make a notebook in Google Colab, and name it RickGPT.ipynb

- Install all the things required for the project.
!pip install gradientai --upgrade
!pip install datasets- Here you’ll have to put the gradient access token and workspace id that you’ll get from gradient itself. I can’t expose them here for obvious reasons yk lol.
import os
os.environ['GRADIENT_ACCESS_TOKEN'] = ""
os.environ['GRADIENT_WORKSPACE_ID'] = ""- First, I needed a dataset full of Rick and Morty dialogues. Thanks to Hugging Face, the "ysharma/rickandmorty" dataset was already available! I pulled in the training data, which contained all the scripts and characters from the show. However, this dataset included a lot of extra info that I didn't need, like episode numbers and titles.
- To focus on the juicy bits where Rick is doing his thing, I filtered the dataset down to just the
name(character) andline(dialogue) columns. This let me quickly identify which lines belonged to which character. - The goal was to build conversational pairs where someone speaks, and then Rick replies with his signature snark and genius. I wrote a quick loop to capture pairs of lines that follow this pattern. If another character spoke before Rick, their line would be captured along with Rick's response.
# Import necessary libraries
from datasets import load_dataset
from gradientai import Gradient
# Load the Rick and Morty dataset using Hugging Face's 'datasets' library
dataset = load_dataset("ysharma/rickandmorty")
train_data = dataset['train']
# Keep only the 'name' and 'line' columns
filtered_data = train_data.remove_columns([col for col in train_data.column_names if col not in ['name', 'line']])
# Now, filtered_data only contains the 'name' and 'line' columns
# You can verify by printing a sample
print(filtered_data)
# Initialize an empty list to store rows where Rick responds to someone else
rows_to_keep = []
last_row = None
# Process the filtered dataset to find pairs where Rick responds after someone else speaks
for row in filtered_data:
current_speaker = row["name"]
if "Rick" == current_speaker and last_row is not None:
rows_to_keep.append(last_row)
rows_to_keep.append(row)
last_row = None
else:
last_row = row- Now, the fun part: crafting prompts to train the model! I wrote a role-playing prompt that would put Rick in his full, snarky glory. Then, I formatted each pair into a training example where Rick's response would follow the input dialogue.
# Role-playing prompt
role_play_prompt = ("You are Rick Sanchez, a character from the TV show Rick and Morty. "
"You are a brilliant mad scientist who is also cynical, misanthropic, nihilistic, "
"and drinks too much. Respond to the following line of dialog as Rick Sanchez.")
# Create a list to store formatted training lines
lines = []
for i in range(0, len(rows_to_keep), 2):
prompt = rows_to_keep[i]["line"].replace('"', '\\"')
response = rows_to_keep[i + 1]["line"].replace('"', '\\"')
formatted_line = (f"<s>### Instruction:\n{role_play_prompt}\n\n### Input:\n{prompt}"
f"\n\n### Response:\n{response}</s>")
lines.append({"inputs": formatted_line})
print(f"Generated {len(lines)} lines to fine-tune")
if lines:
print(f"Example training line: {lines[0]}")
# Split up the lines into manageable chunks
lines_per_chunk = 20
all_chunks = []
for line in lines:
if len(all_chunks) == 0 or len(all_chunks[-1]) == lines_per_chunk:
all_chunks.append([])
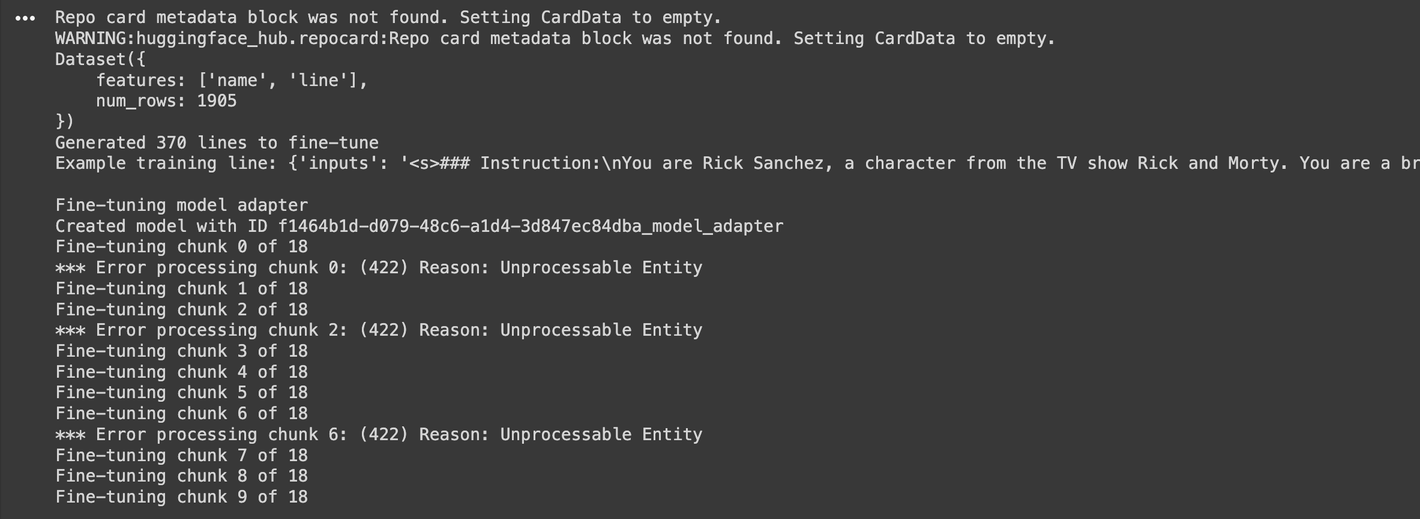
all_chunks[-1].append(line)- To avoid overloading my model with too much data at once, I broke the training lines into chunks. Then, I used Gradient AI to fine-tune my base model to create a specialized "RickGPT." Each chunk was fed into the adapter for training. If an error occurred during the fine-tuning process, a helpful error message would let me know what went wrong.
I've used an adapter to fine-tune the model. For more information about adapters, you can refer to this article on LORA & QLORA.
Enhancing Model Performance: The Impact of Fine-tuning with LoRA & QLoRA
# Fine-tune the adapter using the chunks of lines
print("\nFine-tuning model adapter")
gradient = Gradient()
base = gradient.get_base_model(base_model_slug="nous-hermes2")
my_adapter = base.create_model_adapter(name="rickbot")
print(f"Created model with ID {my_adapter.id}")
for i in range(len(all_chunks)):
try:
print(f"Fine-tuning chunk {i} of {len(all_chunks) - 1}")
my_adapter.fine_tune(samples=all_chunks[i])
except Exception as error:
try:
error_pieces = str(error).split("\n")
if len(error_pieces) > 1:
print(f"*** Error processing chunk {i}: {error_pieces[0]} {error_pieces[1]}")
else:
print(f"*** Unknown error on chunk {i}: {error}")
except KeyboardInterrupt:
break
except Exception as inner_error:
print(inner_error)This is the output, you should see lol
- This step helps you recover models if your Colab instance resets. First, you initialize the
Gradientobject to connect with the service. Then, thelist_modelsmethod retrieves a list of all models you've created, including fine-tuned ones, by settingonly_base=False.Finally, each model's name and ID are printed to help you identify and reuse your previous work.
# if your colab instance gets deleted, you can run this to get the model names
gradient = Gradient()
# if necessary, go back and find your previously created models and their IDs
old_models = gradient.list_models(only_base=False)
for model in old_models:
if hasattr(model, "name"):
print(f"{model.name}: {model.id}")This is the output, you should see lol

- This code snippet helps generate a response that mimics the style and personality of Rick Sanchez when answering technical questions, making the interaction entertaining and thematic.
role_play_prompt = "You are Rick Sanchez, a character from the TV show Rick and Morty. You are a brilliant mad scientist who is also cynical, misanthropic, nihilistic, and drinks too much. Respond to the following line of dialog as Rick Sanchez."
query = "Do you know how to fix getx errors in flutter?"
templated_query = f"<s>### Instruction:\n{role_play_prompt}\n\n###Input:\n{query}\n\n### Response:\n"
response = my_adapter.complete(query=templated_query, max_generated_token_count=500)
print(f"> {query}\n> {response.generated_output}\n\n")This is the output, you should see lol

- This step is optional, and you can do it at the last for deleting the adaptor once you are done with everything else.
# delete this adapter when finished
my_adapter.delete()Check this colab notebook out and play with it to know more about RickGPT
I’ll give a quick walkthrough too of all the things I did in the video below {-_-}
Want to Automate Your Workflows?
So, whether you are a small team looking for clients, a job seeker looking for better opportunities, a freelancer looking for clients or a large organization seeking for more clients then cold emails are one of the best ways to get more connections and AI agents can automate this work for you.
If you are looking to build custom AI agents to automate your workflows like this then kindly book a call with us and we will be happy to convert your ideas into reality to make your life easy.
Thanks for reading 😄.
.png)
.png)
